🕸️ Knowledge Graph
Transform TMDB metadata into distribution-ready feeds
Distribution Readiness
Distribution Pipeline
Browse Movies
No Movies Found
Start by ingesting data from the GCS bucket
Genres
No Genres Found
Genres will appear after data ingestion
📡 Feed Preview
Preview distribution feeds in platform-specific formats
Netflix IMF Package
Interoperable Master Format (SMPTE ST 2067) for Netflix content delivery
Amazon MEC Feed
Media Entertainment Core (EMA Avails v2.5) for Amazon Prime Video
FAST MRSS Feed
Media RSS 2.0 for Pluto TV, Tubi, Roku Channel, Samsung TV Plus
Sample Feed Output
🔍 Semantic Search
Find movies using natural language powered by Vertex AI embeddings
How Semantic Search Works
Unlike keyword search, semantic search understands the meaning of your query. Your query and movie descriptions are converted to 768-dimensional vectors using Vertex AI embeddings, then matched by cosine similarity. This finds movies that are conceptually related, even without exact word matches.
Found matches
No Matches Found
Try a different query or check if movies have been ingested with embeddings
AI-Powered Movie Discovery
Enter a natural language description to find semantically similar movies
Searching...
Generating query embedding and finding similar movies
⚙️ Data Ingestion
Process TMDB dataset into knowledge graph
GCP Access Disabled
This feature is no longer active as we no longer have access to the Hackathon GCP account. The data ingestion controls below are shown for demonstration purposes only. The application now runs on pre-exported data hosted on Netlify.
Data Source
Ingestion Controls
Embeddings will be generated using Vertex AI
This adds ~2 seconds per batch of 5 movies. For 100k movies, expect ~5-6 hours total processing time.
Ingestion Result
Semantic Search Ready!
You can now use the Semantic Search tab to find movies by description
🕸️ Knowledge Graph Visualization
Explore relationships between movies, genres, companies, and more
Node Types
No Graph Data
Ingest some movies first to visualize the knowledge graph
🏆 London Chapter Team Output
Built in 48-72 hours during the Global AI Hackathon
The Future of Media Discovery & Distribution
A unified platform addressing the $2.4 billion media metadata crisis through AI-powered discovery, recommendation, and distribution.
🎯 Integrated Platform Vision
Five interconnected AI modules working together to revolutionize how content is discovered, recommended, experienced, and distributed globally.

AI-Powered Media Discovery
No more endless scrolling. Users select images that catch their eye, and AI analyzes behavior in real-time — clicks, hovers, and interaction patterns — to understand preferences in just 12 seconds.
- ✓ Visual-first preference capture
- ✓ Real-time behavioral AI analysis
- ✓ Instant personalization without questionnaires

Always-On AI Viewing Companion
An AI that sees, hears, and understands. The companion streams video frames to Gemini at 1fps, captures voice via Web Audio API, and provides deep narrative context about every film.
- ✓ Visual awareness with real-time frame analysis
- ✓ Low-latency voice interaction
- ✓ Deep narrative context and Q&A
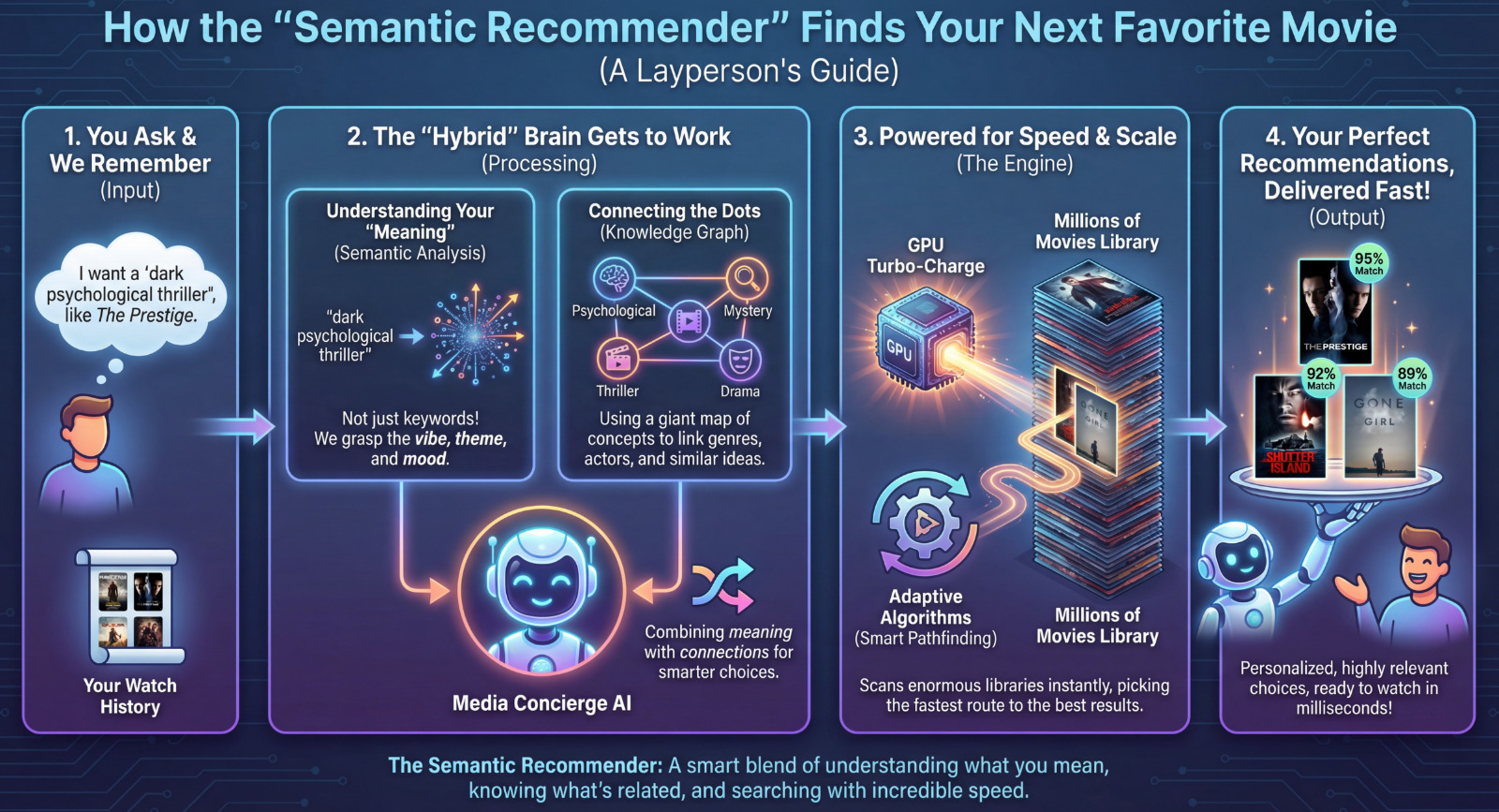
High-Performance Semantic Recommender
Understanding meaning, not just keywords. A hybrid brain combining semantic analysis with knowledge graph connections, powered by GPU turbo-charge to scan millions of movies instantly.
- ✓ 316,000 queries/second throughput
- ✓ <1ms latency for all retrievals
- ✓ Understands vibe, theme, and mood
CR-HyperVR: Smarter Film Recommendations
Solving the cold-start problem. A hybrid recommender blending semantic search with hypergraph signals, using an optimized ONNX model that runs on CPU — no expensive GPUs required.
- ✓ Low latency & cost on CPU
- ✓ Works even with sparse user data
- ✓ Score fusion & ranking for perfect results
UMMID: Unifying Global Media Distribution
Solving the $2.4B metadata crisis. An AI-powered knowledge graph that ingests, enriches, and distributes compliant metadata feeds to Netflix (IMF), Amazon (MEC), and FAST channels (MRSS).
- ✓ Prevents 40% revenue loss from metadata failures
- ✓ 10x faster semantic content discovery
- ✓ 85% reduction in data processing costs
Agent Ready Web (ARW)
Infrastructure for the AI agent economy. Enabling efficient agent-web interaction with 85% token reduction, full observability of agent traffic, and safe commercial transactions.
- ✓ 10x faster content discovery for AI agents
- ✓ Full agent traffic observability
- ✓ Safe agent commercial transactions
🎬 Ready to Transform Media Discovery?
Our integrated platform combines AI-powered preference capture, intelligent viewing companions, high-performance recommendations, and global distribution — all built by industry experts passionate about solving real problems.
🏆 London Chapter Team — TV5MONDE Agentics Foundation
Nexus-UMMID Knowledge Graph
Unified Media Metadata Integration & Distribution (UMMID)
AI-powered metadata management and distribution pipeline for global content delivery across Netflix, Amazon, and FAST platforms.
🚨 The Problem: Metadata Distribution Crisis
The Last Mile Challenge: While content ownership is centralized, distribution occurs through fragmented third-party ecosystems (SVOD, AVOD, FAST, linear TV). Each platform—Netflix, Amazon, Pluto TV—maintains unique, rigid delivery specifications. Metadata accepted by one platform faces rejection from another if formatted incorrectly, causing costly delays and lost revenue windows.
✅ Our Solution: Unified Knowledge Graph
Hypergraph Architecture
Unified data model connecting movies, genres, actors, and companies through multi-dimensional relationships—eliminating silos
AI-Powered Discovery
768-dimensional Vertex AI embeddings enable semantic search, finding content by meaning rather than keywords
Auto-Validation & Export
Automated compliance checking and feed generation for Netflix IMF, Amazon MEC, and FAST MRSS standards
📈 Business Outcomes
⚡ How It Works
Ingest
Import metadata from TMDB dataset stored in GCS bucket
Build Graph
Create nodes and edges connecting movies to genres, companies, countries
AI Enrichment
Generate semantic embeddings via Vertex AI for intelligent search
Distribute
Validate and export to Netflix, Amazon, and FAST platforms
📊 Live System Metrics
🎯 Distribution Platform Standards
Netflix IMF
- • Interoperable Master Format
- • 50+ character synopsis required
- • Runtime validation
- • Release date metadata
- • 4K/HDR specifications
Amazon MEC
- • Media Exchange Container
- • Title and synopsis validation
- • Genre classification
- • Runtime requirements
- • XML/JSON manifest
FAST MRSS
- • Media RSS Feed Standard
- • Pluto TV / Tubi compatible
- • Thumbnail requirements
- • Duration metadata
- • Real-time feed updates
🏗️ System Architecture
Backend Services
- Cloud Run API (Node.js/TypeScript)
- Firestore (Knowledge Graph Storage)
- Vertex AI (Embedding Generation)
- Cloud Storage (Dataset Source)
Frontend Stack
- Alpine.js (Reactive UI)
- Tailwind CSS (Styling)
- vis.js Network (Graph Visualization)
- Cloud Storage (Static Hosting)
Built for TV5MONDE Agentics Foundation Hackathon 2025 | Powered by Google Cloud Platform during the Hackathon and now moved to Netlify